
- Onderzoek , Sluitstuk
- 4 min
- 16/01/2025

Sluitstuk | Bijzondere patronen ontdekken in data
Hoe ontdek je verborgen patronen in grote hoeveelheden data? TU/e-onderzoeker Rianne Schouten ontwikkelde een methode om uitzonderlijke groepen zichtbaar te maken. Of het nu gaat om jongeren met afwijkend drinkgedrag of om kinderen met leerproblemen, haar werk onthult verrassende inzichten die kunnen bijdragen aan praktische oplossingen in de samenleving. Vandaag verdedigt ze haar proefschrift aan de faculteit Mathematics & Computer Science.
“Tijdens mijn master Methodologie en Statistiek aan de Universiteit Utrecht leerde ik veel over het verzamelen en analyseren van data”, vertelt Rianne Schouten. “Ik werkte voornamelijk met data over echte mensen, waarvoor veel moeite was gedaan om ze te verzamelen. Toen ik solliciteerde naar een PhD-positie op het gebied van Exceptional Model Mining (EMM), was dat een compleet nieuw terrein voor me, maar het sprak me meteen aan.”
Ze legt uit dat het idee achter EMM draait om het identificeren van subgroepen in datasets die zich anders gedragen dan de rest. “Waar traditionele statistische methodes zich richten op het analyseren van de hele dataset en een beeld geven van de ‘gemiddelde persoon’, biedt EMM de mogelijkheid om juist uitzonderlijke groepen zichtbaar te maken. Bijvoorbeeld groepen patiënten bij wie een medicijn anders werkt, of leerlingen met een afwijkende leercurve. Deze exceptionele groepen blijven vaak onzichtbaar in traditionele analyses, maar met EMM kun je ze opsporen.”
Schouten benadrukt dat EMM een andere kijk biedt dan traditionele statistiek, waarin alles draait om algemene trends in de gehele populatie. “EMM zoekt juist naar patronen in kleine delen van een dataset”, legt ze uit. “Met deze techniek krijg je veel meer inzicht in de diversiteit binnen een populatie. Niet iedereen is hetzelfde, en juist door te onderzoeken welke groepen mensen anders zijn, kun je begrijpen waarom dat zo is. EMM draait om twee aspecten: het opsporen van exceptioneel gedrag én het beschrijven van die subgroepen, zodat ze duidelijk te onderscheiden zijn van de rest.”
Hiërarchische data
“Er waren al methodes om afwijkende patronen in datasets te ontdekken, maar deze waren met name geschikt voor zogeheten ‘independent data,’ oftewel datasets waar data elkaar niet beïnvloeden”, legt ze uit. “In de praktijk is dat vaak niet het geval. Dan heb je te maken met hiërarchische data, waarbij elementen binnen een dataset van elkaar afhankelijk zijn. Denk aan leerlingen die dezelfde docent hebben: de lesstijl en communicatie van die docent kunnen invloed hebben op de prestaties van de leerlingen. Hier zijn data niet onafhankelijk en vertonen ze meer gelijkenissen.”
Als je deze afhankelijkheden niet meeneemt, loop je het risico op een vertekend beeld en mis je belangrijke patronen. Schouten ontwikkelde daarom een nieuwe methode om interessante subgroepen te ontdekken in hiërarchische datasets. Daarnaast paste ze deze methode toe op verschillende datasets, wat leidde tot waardevolle inzichten.
Alcoholgebruik van jongeren
Voor haar proefschrift werkte ze samen met het Trimbos-instituut, dat jaarlijks data verzamelt via vragenlijsten onder Nederlandse jongeren. Deze datasets bieden een rijke basis voor uiteenlopende analyses. Terwijl ze haar proefschrift openslaat, wijst Schouten naar een grafiek die het alcoholgebruik van jongeren tussen de 12 en 16 jaar in kaart brengt.
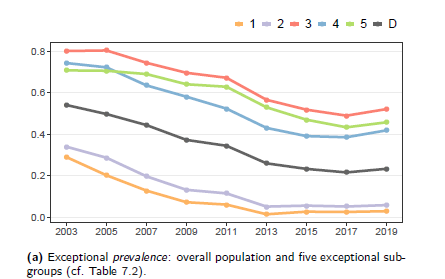
“De x-as toont verschillende jaren en de y-as geeft het percentage jongeren weer dat in de afgelopen vier weken alcohol heeft gedronken”, licht ze toe. De grafiek laat een gestage daling zien in alcoholgebruik, wat het resultaat is van overheidsmaatregelen. Maar na verloop van tijd vlakt deze daling af: het percentage jongeren dat alcohol drinkt, stagneert.
“Om te begrijpen waarom deze trend stopt, heb ik een methode ontwikkeld om subgroepen te identificeren die een afwijkend gedragspatroon vertonen”, vertelt Schouten. Ze wijst naar een rode lijn in de grafiek, die 15- en 16-jarigen vertegenwoordigt die significant meer drinken dan gemiddeld. “Hoewel leeftijd een voor de hand liggende verklaring lijkt, willen we juist subgroepen vinden die verrassender zijn en afwijkende patronen laten zien.”
Door verschillende variabelen – persoonlijke kenmerken zoals geslacht, type opleiding of thuissituatie – te combineren, kun je unieke subgroepen beschrijven. “Bijvoorbeeld: meisjes jonger dan 13 die nooit hebben gespijbeld”, illustreert ze. “Datasets bevatten zoveel subgroepen, dat je die niet allemaal handmatig kunt analyseren. Met wiskundige methoden kun je gericht zoeken naar de meest interessante subgroepen.”
Een opvallende ontdekking was dat jongeren in kleine dorpen een sterkere daling in alcoholgebruik laten zien dan gemiddeld. “Dit is waardevolle informatie”, benadrukt Schouten. “Het biedt aanknopingspunten om te onderzoeken waarom deze groep succesvol is in het verminderen van alcoholgebruik, en hoe die inzichten kunnen worden toegepast op andere groepen.”
Dyscalculie opsporen
Een ander voorbeeld komt uit een samenwerking met Finse onderzoekers, die een digitale leeromgeving ontwikkelen voor wiskundige taken op scholen. “Zo’n omgeving genereert enorm veel data”, legt Schouten uit. “Je kunt zien hoe snel leerlingen antwoorden geven en of die correct zijn.”
Met haar methode identificeerde ze subgroepen leerlingen die afwijkend gedrag vertoonden, zoals moeite met specifieke vraagtypen. “We vonden een groep die symptomen van dyscalculie vertoont”, zegt ze. “Deze informatie kan worden teruggekoppeld aan docenten, zodat zij gerichter begeleiding kunnen bieden.”
Een multidisciplinaire aanpak
Het onderzoek van Schouten illustreert het belang van samenwerking tussen disciplines. “Ik focus me op het ontwikkelen van de methode om uitzonderlijke patronen in datasets op te sporen”, legt ze uit. “Maar die patronen zijn vaak het beginpunt. De inzichten die we genereren, geef ik door aan experts zoals sociologen of gedragswetenschappers, zodat zij ermee aan de slag kunnen.”
Vooral bij maatschappelijke vraagstukken, zoals alcoholgebruik onder jongeren of leerproblemen, is een interdisciplinaire aanpak essentieel. “Mijn werk gaat om het zichtbaar maken van de verborgen structuur in data, maar de uiteindelijke interpretatie en toepassing van die inzichten is iets wat in nauwe samenwerking met andere experts gebeurt”, aldus Schouten. Ze hoopt dat haar onderzoek niet alleen nieuwe inzichten oplevert, maar ook bijdraagt aan concrete oplossingen voor maatschappelijke vraagstukken.“Ik vind het heel belangrijk dat mijn werk nuttig en relevant is voor de maatschappij.”
PhD in the picture

{kind=link}
Wat staat er op je proefschriftkaft?
“De poppetjes op de cover symboliseren verschillende personen in onze samenleving. Door ze verschillende kleuren te geven, kun je de subgroepen van elkaar onderscheiden. Het laat duidelijk zien dat niet iedereen hetzelfde is.”
Je bent op een verjaardagsfeestje. Hoe leg je uit wat je onderzoekt?
“Ik zoek naar subgroepen in de samenleving die zich anders gedragen dan de rest.”
Hoe blaas je naast je onderzoek stoom af?
“Ik lees graag - vooral romans en fantasy. Het helpt me om even helemaal in een andere wereld te duiken.”
Welk advies zou je aan toekomstige promovendi willen geven?
“Investeer vanaf het begin in een goede communicatie met je promotoren. Dat levert je later veel op. Sommige mensen willen zich eerst bewijzen voordat ze assertiever durven zijn, maar ik denk dat je vanaf dag één duidelijk en open moet communiceren. De resultaten komen dan vanzelf. Ik had het geluk met promotoren die altijd openstonden voor feedback.”
Wat is je volgende hoofdstuk?
“Ik blijf als postdoc aan de TU/e om mijn onderzoek voort te zetten. We willen onze methode verder ontwikkelen en uiteindelijk een praktische tool creëren. Stel je voor dat docenten met één druk op de knop kunnen zien of een leerling uitzonderlijk gedrag vertoont en waar mogelijke knelpunten liggen. Dan wordt het echt toepasbaar, in plaats van alleen een theoretisch concept in een proefschrift.”
Discussie